

Computer vision, one of the most powerful and captivating forms of AI, is likely something you've encountered in various ways without even realizing it. This technology aims to mimic certain aspects of the human visual system, allowing computers to recognize and analyze objects in images and videos in a manner similar to humans. In the past, computer vision was only capable of limited functionality.
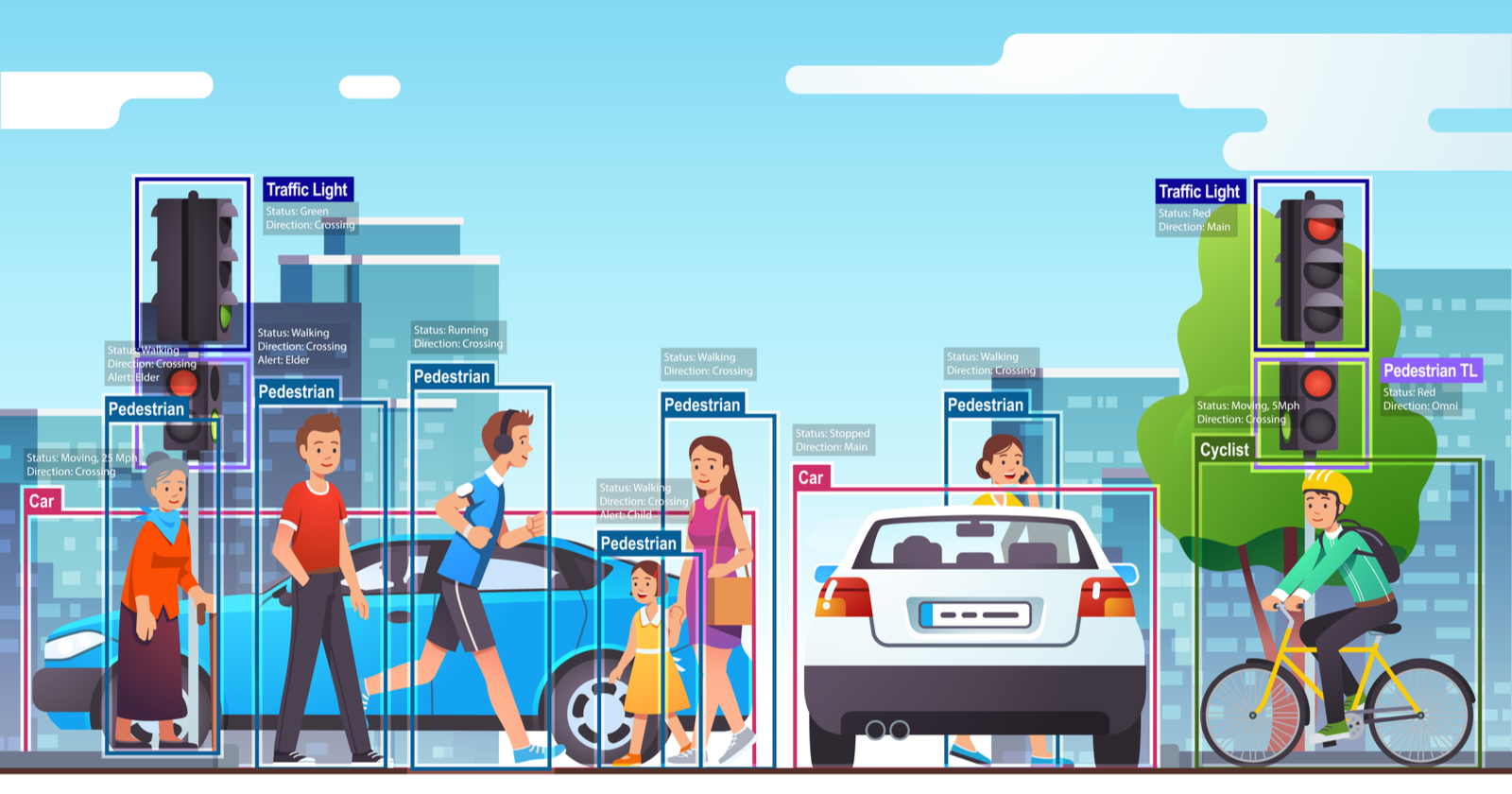
However, with recent advancements in artificial intelligence, deep learning, and neural networks, this field has made significant strides and has even surpassed human abilities in certain tasks related to object detection and labeling. So let’s dive into the world of Computer Vision.
What is Computer Vision? How does it work?
Computer vision is a field of study in artificial intelligence that focuses on enabling computers to interpret and understand the visual world in the same way that humans do. It involves developing algorithms and models that can analyze digital images and videos to recognize and classify objects, track their movements, and extract useful information from visual data.
This field of artificial intelligence aims to train computers to comprehend the visual world. By utilizing digital images and deep learning models, computers can accurately recognize and categorize objects, as well as respond to them.
The goal of computer vision in AI is to create automated systems that can interpret visual data, such as photographs or videos, in a way that mirrors human perception. This involves teaching computers to analyze and understand images at a pixel level, which serves as the foundation of this field. From a technical standpoint, computers work to extract visual data, process it, and analyze the results using advanced software programs.

As shown above computer vision works by using algorithms and models that are trained on large sets of visual data to interpret and understand digital images and videos. At a high level, the process involves the following steps:
- Image acquisition: This involves capturing digital images or videos using cameras, sensors, or other devices.
- Preprocessing: The raw data from the images is preprocessed, which involves tasks like noise reduction, image enhancement, and normalization.
- Feature extraction: The algorithm extracts important features from the image, such as edges, corners, and textures. These features help to identify and classify objects in the image.
- Object recognition and tracking: The algorithm uses the extracted features to identify and recognize objects in the image, and can also track their movements over time.
- Interpretation and decision making: The algorithm analyzes the identified objects and their movements to extract useful information and make decisions or predictions based on that information.
The process of training a computer vision system involves feeding it large amounts of labeled data, which helps the system learn how to identify and classify objects in different situations. As the system continues to learn from more data, its accuracy and performance improve over time.
What are the applications of Computer Vision?
Computer vision has a wide range of applications across various fields. Some of the most common applications of computer vision include:
- Augmented and virtual reality: Computer vision is a key technology in augmented and virtual reality applications, allowing devices to recognize and interact with the physical environment.
- Super-resolution Imaging: Super resolution imaging is a set of techniques used to improve the spatial resolution of digital images beyond the physical limitations of the imaging system. In other words, it allows us to obtain higher-quality images with more detail and clarity than what would normally be possible with a given imaging system.
- Optical Character Recognition (OCR): It is a technology that allows computers to read and recognize text in digital images or scanned documents. OCR works by analyzing the shapes and patterns of characters in an image, and then using machine learning algorithms to convert those patterns into text that can be edited and searched.OCR is particularly useful for automating tasks that would otherwise require manual data entry, such as digitizing old records or extracting text from handwritten documents.
- Object recognition: Computer vision can be used to recognize and classify objects in images and videos. This technology is used in facial recognition software, and security systems. One of these real world applications of facial recognition can be seen in the Google self-driving project called Waymo.
- Motion analysis: Computer vision can track and analyze the movement of objects in videos, which is useful for applications like video surveillance and sports analysis.
- Healthcare: Computer vision can be used to analyze medical images, such as X-rays and MRI scans, to identify and diagnose medical conditions.
- Quality control: Computer vision can be used to inspect products for defects in manufacturing processes, such as identifying scratches or dents on surfaces.
- Robotics: Computer vision is used in robotics to enable machines to identify and interact with objects in the environment.
- Agriculture: Computer vision can be used to monitor crop growth and health, identify pests, and optimize crop yield.
Overall, computer vision has a wide range of potential applications across industries, and as the technology continues to improve, we can expect to see more and more innovative uses of this powerful technology.
What does a Computer Vision Engineer do?

Computer vision engineers are responsible for utilizing computer vision and machine learning research to address real-world problems. They use extensive data and statistics to tackle complex tasks and implement supervised or unsupervised learning as part of their computer vision work.
Computer Vision engineers spend a significant amount of time researching and developing machine learning and computer vision systems for their clients and larger corporations. They collaborate closely with other professionals, often from non-computer science fields, to incorporate innovative embedded architectures into existing programs and devices.
In general, computer vision engineers possess a wealth of experience with various systems, including image recognition, machine learning, Edge AI, networking and communication, deep learning, artificial intelligence, advanced computing, image annotation, data science, and image/video segmentation.
What are the Roles and responsibilities of a Computer Vision Engineer?
Computer vision engineers are able to automate various functions using programming that the human visual system can do to fulfill a task, like creating the adaptive cruise control features on a car. The tasks required of computer vision engineers often involve skills dependent on linear algebra math libraries and a foundational understanding of algorithms and mathematical processes.
The job requires working efficiently in a collaborative setting. Like many other careers in computer science, computer vision engineering requires high levels of self-motivation and the ability to coordinate with other teammates. Computer vision engineers often find clever ways to incorporate artificial intelligence into different areas. Some of their responsibilities include:
- Develop, test, debug, deploy, and maintain computer vision algorithms and hardware for different environments.
- Develop automated vision algorithms, especially for work with robots and autonomous hardware systems.
- Gather and optimize analytics from computer vision algorithms to improve their performance.
- Study real-world problems and propose practical, efficient, and creative solutions to those problems.
- Build technical documentation for computer vision systems for end-users to understand how these systems work and how to use them.
- Manage large and small-scale computer vision projects, define project requirements, prepare budgets, and run technical development teams.
- Adapting existing technology to make it perform specific tasks
- Developing new systems to improve the efficacy of visual technology
- Improving their understanding of how visual recognition systems are used
- Researching new technological advancements in the field of vision engineering
- Reviewing and assessing the output of engineering models to establish which is most effective
What skills do Computer Vision Engineers have?
This is a complex job that combines high levels of knowledge from a few different disciplines, primarily mathematics and computer science. They key skills are knowledge of mathematics, specifically data science, calculus, and linear algebra. It also requires in-depth knowledge of linear algebra libraries, ML libraries, and programming languages such as C++, Python, Java.
Other skills that are required for this job include:
- Knowledge of process automation and AI pipeline designing.
- 1+ years of experience in Artificial Intelligence projects
- Programming skills (Python, C++, MATLAB) is a must
- Ability to develop image analysis algorithms
- Ability to develop Deep Learning frameworks to solve problems
- Design and create platforms for image processing and visualization
- Knowledge of computer vision libraries
- Understanding of dataflow programming
- Database management skills
- Software engineering experience
- Critical thinking skills
- Ability to drive projects independently and with the team
- Working knowledge of tools like git, docker etc.
- Excellent written and verbal communication skills
- Degrees in computer science, electrical engineering preferred
What tools and technologies do Computer Vision Engineers use?

Cloud technologies have played an important role in the widespread adoption of computer vision. Needless to add, the major cloud service providers like Microsoft, Google, and IBM have their own computer vision solutions. However, there are lots of open-source tools available for developing computer vision systems. Let’s see some of the most popular open source tools used by Computer Vision engineers:
Frameworks & Libraries
Open Source Computer Vision Library (OpenCV): It is an open-source computer vision library that contains many different functions for computer vision and machine learning. OpenCV has many different algorithms related to computer vision that can perform a variety of tasks including facial detection and recognition, object identification, monitoring moving objects, tracking camera movements, tracking eye movements, extracting 3D models of objects, creating an augmented reality overlay with a scenery, recognizing similar images in an image database, etc. OpenCV has interfaces for C++, Python, Java, MATLAB etc. and it supports various operating systems such as Windows, Android, Mac OS, Linux, etc.
SimpleCV: It is a framework for open-source machine vision using the OpenCV library and Python as the programming language. It is designed for casual users who have no experience in writing programs. Cameras, images, video streams, and video files are interoperable on SimpleCV and manipulations are very fast.
Keras: It is an open-source neural network library developed in Python. It is optimized to reduce cognitive load and concentrates on being user-friendly, modular, and extensible. It can also run on top of Microsoft Cognitive Toolkit, TensorFlow, R, PlaidML, or Theano.
BoofCV: is an open-source Java library written from scratch for real-time robotics and computer vision applications for both academic and business use. It is released under Apache Licence 2.0 and includes functionalities like low-level image processing, feature detection, and tracking, camera calibration, classification, and recognition.
GPUImage: It is a framework or rather, an iOS library that allows you to apply GPU-accelerated effects and filters to images, live motion video, and movies. It is built on OpenGL ES 2.0. Running custom filters on a GPU calls for a lot of code to set up and maintain. GPUImage cuts down on all of that boilerplate and gets the job done for you.
Other Libraries: NumPy, SciPy, and Pandas are libraries that are commonly used for mathematical and statistical computations in computer vision.
Deep learning models
Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are deep learning models that are used in computer vision for image classification, object detection, and segmentation.
Tools
TensorFlow: It is the most popular deep learning library because of the simplicity of its API. It is a free open source library for data streams and differential programming. TensorFlow 2.0 supports picture and speech recognition, object detection, reinforced learning, and recommendations. Its reference model makes it easier to start building solutions.
MATLAB: It is a multi-paradigm numerical computing environment and proprietary programming language developed by MathWorks. It allows matrix manipulation, plotting of functions and data, and creation of user interfaces and implementation of algorithms. It also allows integration with programs written in other languages. It is widely used in research as prototyping is very easy and quick.
CUDA: It is a parallel computing and application programming interface model created by NVIDIA, the market leader in GPUs. It delivers incredible performance using the GPU. NVIDIA Performance Primitives library is a part of CUDA and contains a set of image, signal, and video processing functions.
You Look Just Once (YOLO): is an object detection system for real-time processing. It is an advanced real-time object detection system.
What is the compensation range for a Computer Vision Engineer?
Currently, the average computer vision engineer in the United States makes US$165,000 in base salary according to Glassdoor.
Boolean search for finding Computer Vision Engineers
A generic boolean search string around terms looks like:
- -job -jobs -sample -examples, to exclude irrelevant results
- (intitle:resume OR intitle:cv) to discover candidates’ online resumes or CVs
- (“computer vision developers” OR “computer vision engineer”) to cover variations of the same job title
Here’s an example of a simple string to find resumes:
(intitle:resume OR intitle:cv) (“computer vision developers” OR “ml engineers”) -job -jobs -sample -templates
With this search string, the words “resume” or “CV” have to appear in the page title. Adding variations of data scientists job roles provides a larger number of relevant results. And, excluding more terms will reduce false positives.
Let’s look at what a final Boolean search looks like using the following fields:
- Job title: (“Computer Vision Developer” OR “Computer Vision” OR “OpenCV Developer” OR “OpenCV Engineer”) AND (“Senior” OR “Lead” OR “Team Lead”)
- Sector: (“Healthcare” OR “VR”)
- Tech Stack: Python, C++, MATLAB
The Boolean search string that can be created using the the knowledge we have gained and the aforementioned fields, applicable to any job board, would resemble the following:
(“Computer Vision Developer” OR “Computer Vision” OR “OpenCV Developer” OR “OpenCV Engineer”) AND (“Senior” OR “Lead” OR “Team Lead”) AND (“Healthcare” OR “VR”) AND (“Python” AND “C++” AND “MATLAB”)
Similarly, some of the complete boolean strings to find Computer Vision Engineers in a particular location, with specific skills etc. are:
- Location - ("Computer Vision Engineer" OR "Computer Vision Developer" OR "Automation Lead") AND ("Machine Learning" OR “ML” OR "AI" OR "Artificial Intelligence") AND ( San Francisco OR New York OR Seattle) NOT (.NET)
- Tech Stack - ("Computer Vision Engineer" OR "Computer Vision Developer" OR "Automation Lead") AND (“Analysis Algorithms” AND “Masters in Computer Science” AND “NumPy” AND (“OpenCV” OR “Keras” OR “SimpleCV”))
By using Boolean search as shown above in combination with other research methods, you can greatly increase your chances of finding the right person for your project.
What are some Sample Interview Questions for Computer Vision engineers?
Hard Skills
Logic & Algorithms
- What are the main steps in a typical Computer Vision pipeline?
- What's the purpose of grayscaling?
- Explain with an example why the inputs in computer vision problems can get huge. Provide a solution to overcome this challenge.
- What are the features likely to be detected by the initial layers of a neural network used for Computer Vision? How is this different from what is detected by the later layers of the neural network?
- Consider a filter [-1 -1 -1; 0 0 0; 1 1 1] used for convolution.What edges will this filter extract from the input image?
- Given a 5x5 image with a 3x3 filter and a padding p=1, what will the size of the resultant image be if a convolutional stride of s= 2 is used?
- What is the basis of the state-of-the-art object detection algorithm YOLO?
- What do you understand by Bundle Adjustment?
Design
- Can you explain what method you might use to evaluate an object localization model?
- How can you evaluate the predictions in an Object Detection model?
- Suggest a way to train a convolutional neural network when you have a quite small dataset.
- How many parameters are to be learned in the pooling layers?
- Explain why mirroring, random cropping, and shearing are some techniques that can help in a computer learning problem.
- How does the Siamese Network help to address the one-shot learning problem?
Programming Languages & Tools
- Which programming languages are not suited to Computer Vision? Why?
- What color to grayscale conversion algorithm does OpenCV employ? What is the logic behind this?
- Write the code to handle the placement of Tetris Blocks in a Tetris game in any programming language of your choice?
- How would you encode a categorical variable with thousands of distinct values?
- Given an array filled with random values, write a function rotate_matrix to rotate the array by 90 degrees in the clockwise direction.
- Build a KNN classification model from scratch
Behavioral / Soft Skills
- Describe a time you were able to improve upon the design that was originally suggested.
- Tell me about the project you are most proud of, and what your contribution was.
- Describe your production deployment process
- Give an example of where you have applied your technical knowledge of Computer Vision in a practical way.
- How did you manage source code?
- What did you do to ensure quality in your deliverables?
- When was the last time you used a utility library from the internet to make your Computer Vision project more productive, and what was it?
About Rocket
Rocket pairs talented recruiters with advanced AI to help companies hit their hiring goals and knows technology recruiting inside out. Rocket is headquartered in the heart of Silicon Valley but has recruiters all over the US & Canada serving the needs of our growing client base across engineering, product management, data science and more through a variety of offerings and solutions.


